- Home
- Hot Issues
- Industrial News
- Edge AI Introduction and examples - Mr. Wang
Edge AI Introduction and examples - Mr. Wang
本文整理了台灣人工智慧學校近幾期技術領袖班所產出的邊緣運算(Edge AI)專題,專題可以分成兩個面向,一是在製造業工廠中的Edge AI應用,另一個是日常生活中的Edge AI應用,同時也針對Edge AI的定義和實作方法做一些簡介。
Edge AI 的發展緣由
傳統上的AI佈署,是將資料集中後,由一個具備強大算力的伺服器進行模型訓練與預測。為了讓更多使用者同時在不同地方存取、使用這台計算機上的模型,我們會將伺服器連網,並讓網路上的使用者能夠依據指定的安全協定連線到伺服器上。
這種將服務架設在雲端伺服器上的應用我們稱為 Cloud AI。
隨著時代演進,Cloud AI形式的AI佈署開始在資料集中所導致的隱私問題,以及通訊的安全與效率等方面受到質疑。
於是捨棄雲端伺服器、而直接在邊緣裝置上進行 AI運算的 Edge AI 概念相應而生。
Edge AI
Edge AI強調的是讓使用者不需要連線到伺服器,而是直接在邊緣裝置應用AI模型,近期甚至可以在邊緣裝置上微調(Fine-tune)或是透過近年提出的聯邦學習(Federated learning)技術,由不同邊緣裝置在不洩漏資料的條件下共同參與模型訓練以找到更好的模型。 *微調 (Fine-tune): 將已經完成訓練的模型,在新獲取的資料上重新訓練,好讓模型的推論結果在當前環境下表現的更好。
舉例來說,邊緣裝置可能是你的手機或是家裡的 Webcam,使用 Edge AI來提供 AI服務,可以保證使用者的隱私不會被第三方獲取。
因為Edge AI在近幾年如此的火紅,台灣人工智慧學校的技術領袖班學員中,有許多的專題使用這個AI的前沿技術,並成功佈署於邊緣裝置上,漂亮的實現了Edge AI的技術,成果十分亮眼。
在本文中會對「工廠生產」以及「日常生活」兩個情境,透過技術領袖班的專題經驗,介紹Edge AI應用。

Edge AI應用在工廠生產: 瑕疵檢測 (物件偵測/影像分割)
AI技術應用在工廠生產的瑕疵檢測有兩個典型的場景:
- 對產線上的產品做立即的瑕疵檢測廠內加工、組立等生產線環節的零件瑕疵檢測(e.g. 螺絲、排線)
- 對AOI(自動光學檢查)設備檢測出的瑕疵產品進行複判在AOI機台自動篩選瑕疵物件後,人工再次判斷是否確實存在瑕疵
AOI與瑕疵檢測
當我們提到對AOI設備檢測出的瑕疵物件進行複判,可能會是應用在像是NB機殼、滑鼠或鍵盤等外觀件的複判上,或是晶圓、面板、SMT等生產瑕疵的複判上。生產線中可能已經存在著透過傳統電腦視覺方法來實現的AOI檢測機台。
考慮AI導入現有產線的情況。當客戶有更高的品質要求,我們會將現有的自動化瑕疵檢測標準提高,但也因此會造成更多的誤殺,於是人工複判的工作會顯得重要且極具負擔,透過AI輔助瑕疵檢測可以進一步減少需要複判的數量。
而當我們提到對產線物件做瑕疵判斷,那表示生產線中原先是沒有AOI機台的,這時候透過AI實作瑕疵檢測就成了品質管控的第一守門員
為什麼要用Edge AI
從系統建置的層面上來看,相較原本包含伺服器、前後端系統、通訊等等的集中式 AI專案,使用 Edge AI在製造現場只需要一個獨立的微型電腦,就可以快速的實現應用。
在工廠端發展的應用,通訊成本和頻寬是很大的限制因素,而Edge AI可以極大幅度的減少甚至不需要通訊,這讓 Edge AI在工廠端的應用有天生的優勢。
Edge AI的應用可以非常有彈性,例如可以將 Edge AI 實作的瑕疵檢測裝置與自走車結合,形成可移動的檢測工作站;又或者將攝像頭佈署在現有的機械手臂上,不須額外佈署繁瑣系統,無痛升級智慧機械手臂。
- 專案目標 : 外觀件 AOI後的複判
- 資料 : 包含瑕疵的多解析度的影像
- 模型 : Yolov4, MaskRCNN
- 平台 : Nvidia平台
實作技巧
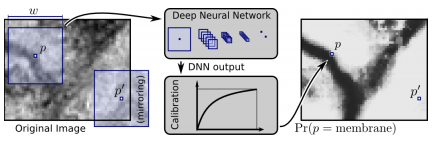
分割成小影像(patch)
當瑕疵在影像中很小的時候,將原始影像切分成更細小的區塊(patch)進行偵測可以有效的提升訓練效果。
用物件偵測的形式執行是最直白的解決方案,以Yolo為例,一開始會先以固定比例分割影像,然後進行候選區域估測(Region Proposal)找到有可能包含物件的區塊(Bounding box),然後透過演算法(e.g. NMS, Non-Maximum Suppression)找到最小的有效區塊,然後才把這個小小的有效區塊放到影像分類的網路中進行預測。
REF:
- YOLOv4: Optimal Speed and Accuracy of Object Detection

用資料增強的手法增加瑕疵影像
增加瑕疵影像的方法可以是單純的將瑕疵區域框選,針對該區域的影像進行影像的轉置或預處理,然後重新貼合到原始影像上。也可以使用像CutMix等等的特殊方法更好的提升訓練效能。
REF:
- CutMix: Regularization Strategy to Train Strong Classifiers
with Localizable Features
Edge AI應用在日常生活
場景一、熱成像影像的行車預警系統 (物件偵測)

行車紀錄器與Edge AI
傳統的行車紀錄器只有錄影功能,而對於錄影過程收集到的資料並沒有善加利用,但事實上,行車紀錄器獲得的影像對駕駛十分有價值,我們可以透過Edge AI與行車紀錄器的結合,產生出令人驚豔的智慧化商品。
使用Edge AI可以保證數據不會被惡意使用或流傳到雲端上,所以很適合與包含隱私資訊(e.g. 行車紀錄器、監視錄影器 )的產品結合,提出一種全新的加值設計,將它與現有的產品做結合,實現智慧化的轉型。
行車紀錄器的加值應用(一)
行車紀錄器與AI結合,一個很好的應用就是行人偵測與預警系統:為了實現輔助駕駛,即時的服務變得十分重要,Edge AI與傳統AI服務相比,不需要將資料回傳雲端、並等待結果,而是完全在邊緣端進行資料處理、預測,因此會有更高的即時性。
關於 AI的電腦視覺專案,如果要將影像回傳伺服器勢必會占用大量頻寬,倘若將影像壓縮可能會減少幀數或畫值。這使得關於影像專案的實作上,Edge AI顯得相當實用。
行車紀錄器的加值應用(二)
在行車預警的場景中,很多時候僅靠RGB的傳統影像並不能很好的識別行人,例如隧道、晚上或者曝光強烈的情況。而熱成像模組已經可以很好的對應不同曝光情況進行對焦和感光度調整,不論是白天或晚上,都有比RGB傳統影像更優異的行人偵測能力。
- 專案目標: 透過熱成像影像進行行人偵測,實現行車預警
- 資料: FLIR 開源熱成像 dataset
- 模型: Yolov4
- 平台: 自有平台
影像預處理
FLIR的熱成像開源資料集為640x512的影像,但專題所使用的熱成像模組卻是另一個規格。不同的解析度會讓模型訓練產生很大的問題,因為單純將影像調整大小並不能很好的將特徵遷移到小的解析度上。
為了解決這個問題,本專題先對資料集中的影像增加高斯噪音(Gausian blur),然後再調整影像大小。並取得相當優異的訓練成果。
結合RGB的深度感測
行車預警系統中,與行人之間的距離也相當重要。而如何用單一鏡頭實現深度感測一直是電腦視覺領域很重要的研究課題,本專題使用深度學習的模型 dispnet、monodepth來進行深度預測。
monodepth是針對影片(video)進行預測的自監督模型,透過對影片中第n幀、第n+1幀的影像計算相似度,並計算兩幀之間的轉移矩陣以估計姿態,最後輸出深度圖。
dispnet繼承自FlowNet,透過卷積神經網路以及光流(optical flow)來實現視差(disparity)以及場景流(scene flow)的估計。(場景流是3D的光流)
REF:
- - https://www.flir.com/oem/adas/adas-dataset-form/
- - A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation - Digging into Self-Supervised Monocular Depth Prediction
場景二、智慧手機架

背景
經常用手機閱讀、或是觀看Youtube影片的現代人,經常會不經意的把手機斜靠在馬克杯、筆記型電腦或是盒裝牛奶上,做一個簡易的手機支撐架。當然,也有朋友直接購買專用的手機架。而有學員就發想,設計一個智慧手機架,利用AI讓手機架可以自動追隨你擺頭的角度,讓你的視線始終與螢幕保持平行,大大減少了長時間觀影的疲勞。
Maker與Edge AI
智慧手機架是一個帶有濃重Maker氣息的專案。動手實作,並快速建立產品雛形,取得反饋並繼續修正,這是Maker手創的重要流程。而Edge AI已經可以結合Maker常用的樹梅派,甚至一些開源的機械手臂,這讓Maker們可以選擇自己熟悉的平台和硬體實現夢想中的專案。
Edge AI與電腦視覺
同樣是電腦視覺的任務,與傳統高深的演算法比較起來,深度學習大大降低了建立模型的難度,尤其是一些常見的生活應用,諸如:口罩偵測、馬克杯辨識、門禁系統等,這些應用甚至不需要特別收集資料,只要使用別人已經開源的資料集就可以實現。
而Edge AI則進一步降低了系統建置的成本。免去了集中式AI繁瑣的系統,用微型開發版(RPI、Jetson nano)和一些易用的python套件,就可以在各種Maker應用中實作AI應用。
- 專案目標: 控制手機架自動跟隨頭部傾斜角度,並結合手勢控制
- 資料: 使用者影像
- 模型: MTCNN、Yolov4、FSA-NET、WHE-Net
- 平台: Nvidia平台、yahboom dofbot
結語
以手機架的控制為例,學員使用的4個模型中,包括偵測人臉的MTCNN、計算頭部姿態的FSA-NET、WHE-Net都是不需要額外收集資料的預訓練模型,而Yolo在應用時,只要收集少量的資料(單一類別約100張以內),就可以有足以實用的準確率。
與傳統的AI系統比較起來,Edge AI不需要伺服器、也不需要前後端串接和資料庫,只需要單一開發版(微型電腦)就可以建立一個AI系統。
如果想要嘗試 Edge AI,筆者會建議從電腦視覺的專案開始實作,硬體的部分不論是 Intel、Google、Nvidia 又或是新創 Kneron 等等在市面上都已經有可以讓一般消費者購買的加速棒或硬體平台,同時也有大量的教學文件,非常好上手,很推薦對 AI 有興趣的人動手玩創意。
圖片來源
- Fig.0: Business vector created by dooder — www.freepik.com
- Fig.1: Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images
- Fig.2: CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
- Fig.3: FLIR Thermal Dataset for Algorithm Training
- Fig.4: 台灣人工智慧學校
- Major organization:
Taiwan Artificial Intelligence Academy Foundation - Co-organizations:
Institute of Information Science and Research Center for Information Technology Innovation - Sponsors:
FPG, CHIMEI, Inventec, EMC, MediaTek and AUO
- Business Time : Tue.~Sat. 09:00~18:00
- Tel:+886 2-8512-3731
- Email:hi@aiacademy.tw
- Address:
14F, No. 141, Sec. 1, Zhongshan Rd., Banqiao Dist., New Taipei City 220684, Taiwan (R.O.C.)
Copyright © Taiwan Artificial Intelligence Academy Foundation